

[統合的運動生成概念]
完全にコンピューター制御されているASIMOから,ZMPを学ぶ。
みなさま,おつかれさまです,舟波真一です。
コラムで統合的運動生成概念,本日は「ZMP:ゼロモーメントポイント」について考えていきます。
ゼロモーメントポイント(ZMP)とは,
二足歩行ロボットの軌道生成法と制御法において,
重力だけでなく慣性力を加えた合力が路面と交わる点のことです。
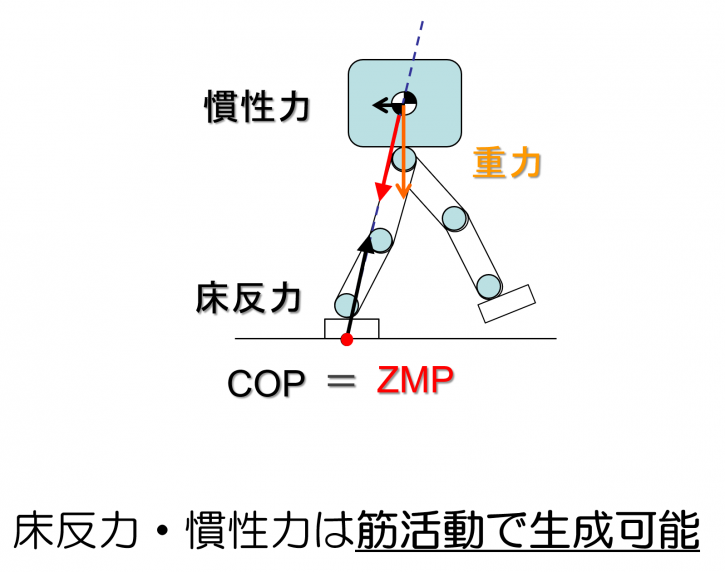
ZMPが足部内に向かうような拘束条件を与えることで二足歩行が実現できます。
ZMPが足部内から外れると動的安定は保てなくなります。
動的安定とは?
片脚支持期において,
支持足の足部内に身体重心が収まっていると,
その状態で静止しても安定できる状態があります。
このような状態をつむぐ歩行を静歩行といい,
我々でも慣れない路面(氷上など)ではそのような歩行をします。
しかし,このような歩行は大変効率が悪いのはお判りでしょう。
我々が通常行っている歩行は動的安定した歩行で,
片足の支持基底面上から身体重心が外れた状態で歩行可能であり,
身体重心の移動を少なくできます。
このように静的には安定できない局面をつむぎながらも,
動的には安定している状態を動的安定といいます。
歩行に限らず,
動的安定のためには「身体重心に対する加速度」つまり「慣性力」をアルゴリズムに組み込む必要があります。
ASIMOは本田技研工業が開発した世界で初めて本格的な2足歩行を実現したロボットであり,
理想の歩行パターンをコンピューターで生成しこれに従うように身体制御を行っています。
この理想的な歩行パターンはCOPとZMPの一致により実現されています。
Check⇒HONDAホームページ
http://www.honda.co.jp/factbook/robot/asimo/200011/04.html
ZMPによる歩行はエネルギー保存則とは無関係な運動法則なので,
エネルギーの消耗が激しく,人が行っている歩行とまったく同じではありません。
またASIMOはプログラムを組んで制御しつくしているロボットであるため,
プログラムに書かれていない環境変化や外乱には対応できません。
しかし予測運動制御による動歩行を実現しており,
COPとZMPが常に一定になるように制御していることだけでも大変な技術であり,
人の運動生成において学ぶべき点が多いです。
また人においても,歩行に限らず床反力を受けての運動生成全般において,
COPとZMPが一致していればその運動(姿勢を含む)は安定して行えているといってよいでしょう。
COPとZMPを一致させるということはどういうことでしょうか?
人にあてはめて考えてみましょう。
重力という外力は我々が自分自身で制御することができない普遍的な力ですが,
床反力や慣性力は我々が神経・筋活動で調節可能な外力です。
床反力は我々の神経筋活動によって「床に対してどのように力を加えているか」の裏返しですし,
慣性力は我々の神経筋活動によって発生させた「加速度」の裏返しとして加速度と反対向きに生成されるみかけ上の力です。
つまり神経筋活動によって床反力を調節してCOPを調整し,
身体重心に対する慣性力を調節することでZMPを調整して,
ZMPとCOPが同じ位置になるようにしているのです。
内力と外力
本来,ふたつ以上の物体があって,その物体間にのみ働く力が「内力」であり,
対になっていて互いに逆向きで同じ大きさの力です。
その他の外から物体にかかる力が「外力」です。
人におけるバイオメカニクスでは,
内力は身体から外に向かって作用する力をさしている場合が多く,
筋線維の収縮や並列・直列弾性要素などが主な力源です。
これに対して身体の外から身体にむけて作用する力が外力であり,
主なものは重力・床反力・慣性力です。
このうち重力は,地球上においてすべての物体にほぼ平等な重力加速度を与える普遍的な外力ですが,
床反力と慣性力は我々が内力によって生成することが可能な外力なのです。
人は,重力を利用しながら,内力を用いて合目的な運動生成にみあった床反力と慣性力を作り出しているといえるのです。
常にCOPとZMPを一致し理想的なバランスを保ったまま歩行し続けられればいいですが,
ASIMOがもし転倒しそうになったとき,
それを立て直すいくつかの方法が用意されています。
- 床反力制御
「床反力制御」は,床の凹凸を吸収しながらも,
倒れそうになったときに足の裏で踏ん張る制御です。
例えば,ロボットがつま先で石を踏んだ場合,COPはつま先側に移動しますが,
このときに床反力制御はつま先側を少し持ち上げてCOPをZMPまで戻します。
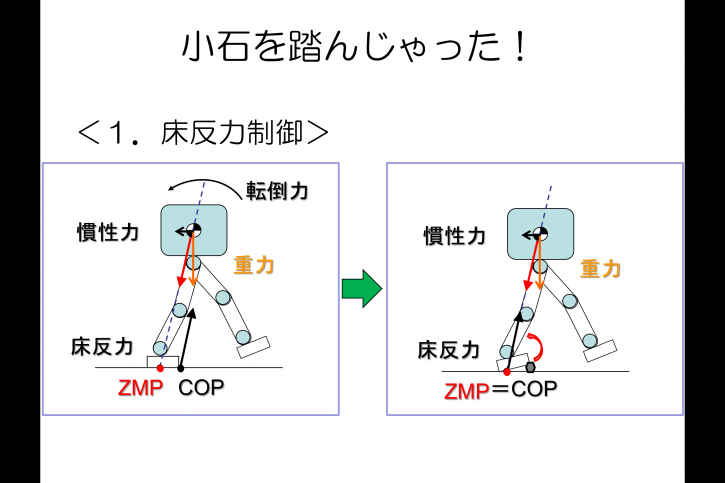
また例えば,何らかの原因でロボットが前傾してしまったときには,
つま先を下げて踏ん張ることにより,COPを前にずらし,姿勢復元力を発生させます。
ただし,COPは足部支持基底面の範囲から越えることができないので,
姿勢の復元力には限界があり,ロボットが大きく傾いた場合には転倒してしまいます。
- 目標ZMP制御と着地位置修正
ロボットが大きく傾いた場合には,さらに「目標ZMP制御」が働いて転倒を防ぎます。
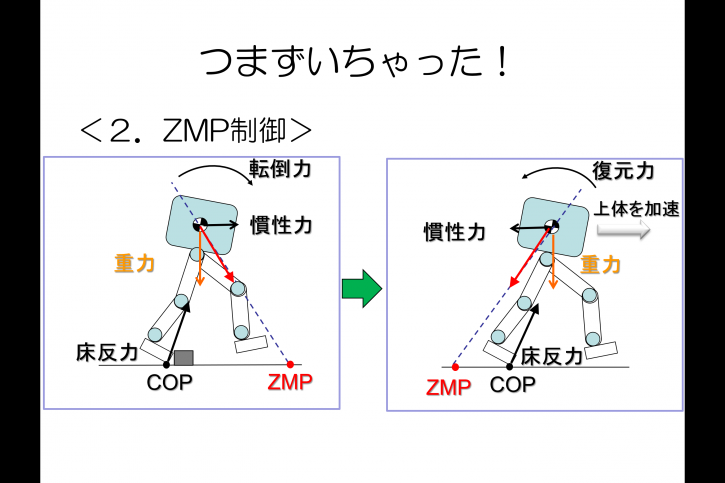
前述のように,ZMPとCOPのズレによって転倒力が発生しますが,
「目標ZMP制御」は,この転倒力を逆に積極的に活用することで安定化を図る制御です。
例えば,上図のように前方に倒れそうな場合,
ロボットの上体を理想の歩行パターンよりもさらに速く強く前方に加速させていきます。
この結果,COGに対して後方への慣性力が生成されてZMPがCOPよりも後方に移動します。
よってCOGを後ろに戻そうとする復元力が働き,姿勢の傾きが回復することになるのです。
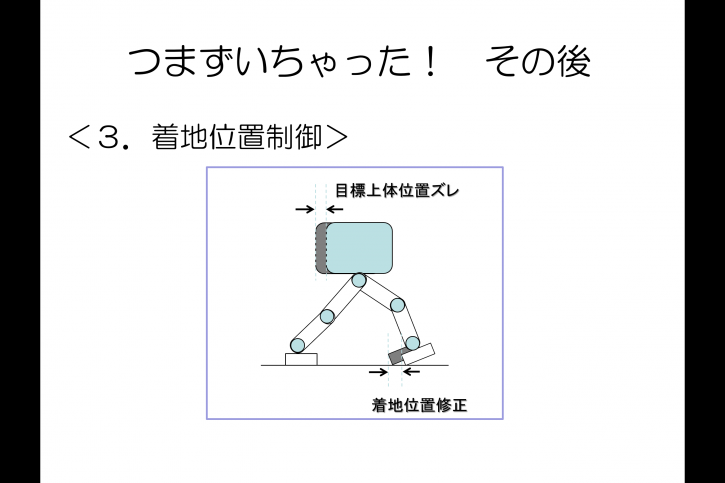
「目標ZMP制御」が働くと,目標としていた上体の位置が,
より強く加速した方向にズレてしまいます。
このとき,いつもと同じ歩幅(理想の歩幅)で次の足を出すと,
上体に対して足が取り残されてしまいます。
「着地位置制御」は,次の一歩を大きく踏み出すことで,
上体と足の理想的な位置関係を取り戻すのです。
我々,人間もこのようなことは無意識的かつ反応的にしかもいとも簡単に行えているはずで,
人の運動生成というのは何と素晴らしいことかと感嘆せずにはいられません。
同時にこのような運動生成システムが,
強い意識を伴う運動学習において,果たして本当に実現できるのであろうかと疑問を感じるのです。
BiNI COMPLEX JAPAN 舟波真一でした。
